Rishi
Rishi
Home
Experience
Events
Projects
Posts
Accomplishments
Contact
Light
Dark
Automatic
Multi-Modal Learning
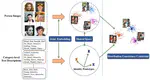
Visuo-Textual Joint Embedding
Contextual Information-rich joint embedding for image and text in a multi-modal vector space using object-text collocation and Relative Position-based Transformer
Code
Scanned Document Classification
Scanned Document Representation Learning using Image-Text-Loc Fusion CNN-Transformer and leveraging it for clustering and classification into 16 document categories
PDF
Code
Cite
×